
On this page
Updated for 2026: I originally wrote this article in 2023 as an overview of dynamic pricing and machine learning. Since then, the field has moved beyond the simple question of whether a model can change prices. The more useful question is: how do we build pricing intelligence that is accurate, governed, explainable, commercially useful, and safe enough to run in the real world?
Dynamic pricing is not simply changing prices with an algorithm. In practice, it is a revenue decision system. It combines demand forecasting, price elasticity, inventory constraints, customer behaviour, competitor signals, margin targets, business rules, experimentation, and human judgment.
Machine learning can improve that system, but only when the business is clear about what decision the model is allowed to make, how quickly prices can change, what constraints must be respected, and how outcomes will be monitored.
If you have ever looked up a plane ticket, waited a few hours, and returned to see a higher price, you have seen dynamic pricing in action. If you have noticed hotel rates change by day, concert tickets become more expensive as supply tightens, or ride-share prices rise during peak demand, you have seen the same idea applied in different markets.
At its simplest, dynamic pricing means adjusting prices based on changing factors such as demand, supply, inventory, seasonality, market conditions, competitor behaviour, and customer behaviour. The goal is usually to improve revenue, profit, capacity utilization, or market competitiveness.
But in a mature organization, the stronger question is not only "what should the price be?" The stronger question is:
What commercial decision should we make now, given the current demand signals, inventory constraints, customer context, and business objectives?
That is where machine learning becomes useful.
Where dynamic pricing works best#
Dynamic pricing is most useful when at least some of the following are true:
- Demand changes meaningfully over time.
- Supply or capacity is limited.
- Customers have different willingness to pay.
- Timing matters.
- Inventory can expire or lose value.
- Competitors frequently change prices.
- The business has enough data to learn demand patterns.
- Prices can be changed without creating operational chaos.
- The business can measure the impact of pricing changes.
This is why dynamic pricing is common in industries such as:
- Airlines and hotels
- Ride-sharing and delivery marketplaces
- E-commerce and retail
- Sports and entertainment tickets
- Subscriptions and SaaS packaging
- Advertising marketplaces
- Energy and utilities
- Freight and logistics
- Digital products and marketplaces
It is also why dynamic pricing is less useful, or more risky, in markets where prices are heavily regulated, supply is commoditized, customer trust is fragile, or price changes are difficult to explain.
Dynamic pricing is powerful when it is connected to the economics of the business. It is dangerous when it is treated as a black-box optimization problem without governance.
Selected research:
- Arnoud den Boer provides a useful survey of the historical origins of dynamic pricing and demand learning across operations research, marketing, economics, econometrics, and computer science: Dynamic pricing and learning: Historical origins, current research, and new directions.

ScienceDirect
Dynamic pricing and learning: Historical origins, current research, and new directions
The topic of dynamic pricing and learning has received a considerable amount of attention in recent years, from different scientific communities. We survey these literature streams: we provide a brief introduction to the historical origins of quantitative research on pricing and demand estimation, point to different subfields in the area of dynamic pricing, and provide an in-depth overview of the available literature on dynamic pricing and learning. Our focus is on the operations research and management science literature, but we also discuss relevant contributions from marketing, economics, econometrics, and computer science. We discuss relations with methodologically related research areas, and identify directions for future research.
- Chenavaz and Dimitrov provide a newer AI-focused literature review that is useful for readers who want a 2025 view of artificial intelligence in dynamic pricing:

Taylor & Francis Online
Artificial intelligence and dynamic pricing: a systematic literature review
With dynamic pricing becoming more widespread across various industries, artificial intelligence has made it even more sophisticated and widespread. The authors conducted a systematic literature review and analyzed a dataset of 95 peer-reviewed articles from international journals selected in Web of Science and Scopus to better understand artificial intelligence’s impact on dynamic pricing. The authors identified four clusters related to financial modeling, market dynamics, commodity markets, and behavior and decision-making. They also found that China has overtaken the USA in the number of published articles. They identified the themes of market simulation investment, crude oil commodity dependence, and behavior traders’ prices. A systematic literature review is essential to understand the impact of artificial intelligence on dynamic pricing and its implications for businesses, consumers, and society.
Dynamic pricing, revenue management, and personalized pricing are not the same thing#
These terms are often used interchangeably, but they are not identical.
Dynamic pricing changes prices based on changing market, demand, supply, or customer conditions.
Revenue management is broader. It includes pricing, inventory control, capacity allocation, segmentation, bundling, channel management, promotions, and timing. Airlines and hotels are classic revenue management businesses because the product is perishable. An empty hotel room last night or an empty airline seat after departure cannot be sold tomorrow.
Personalized pricing changes the offer or price based on customer-level information. This can include browsing behaviour, purchase history, loyalty status, location, risk profile, or predicted willingness to pay.
Personalized pricing can be commercially attractive, but it is also the most sensitive. It can create customer trust issues, fairness concerns, legal risk, and reputational damage if customers feel they are being manipulated.
A useful way to think about the hierarchy is:
Revenue management
includes dynamic pricing
may include personalized pricing
Not every business should use personalized pricing. Not every dynamic pricing system should be fully automated. And not every revenue optimization problem requires a complex reinforcement learning model.
Selected research:
- Ferreira, Lee, and Simchi-Levi show how demand forecasting and price optimization can be implemented in a real online retail environment. Their Rue La La field experiment estimated a revenue increase of about 9.7 percent for the test group:

INFORMS.org PubsO
Analytics for an Online Retailer: Demand Forecasting and Price Optimization
We present our work with an online retailer, Rue La La, as an example of how a retailer can use its wealth of data to optimize pricing decisions on a daily basis. Rue La La is in the online fashion sample sales industry, where they offer extremely limited-time discounts on designer apparel and accessories. One of the retailer’s main challenges is pricing and predicting demand for products that it has never sold before, which account for the majority of sales and revenue. To tackle this challenge, we use machine learning techniques to estimate historical lost sales and predict future demand of new products. The nonparametric structure of our demand prediction model, along with the dependence of a product’s demand on the price of competing products, pose new challenges on translating the demand forecasts into a pricing policy. We develop an algorithm to efficiently solve the subsequent multiproduct price optimization that incorporates reference price effects, and we create and implement this algorithm into a pricing decision support tool for Rue La La’s daily use. We conduct a field experiment and find that sales does not decrease because of implementing tool recommended price increases for medium and high price point products. Finally, we estimate an increase in revenue of the test group by approximately 9.7% with an associated 90% confidence interval of [2.3%, 17.8%].
- Ban and Keskin study personalized dynamic pricing with high-dimensional customer features and heterogeneous elasticity:
Elsevier SSRN
Personalized Dynamic Pricing with Machine Learning: High Dimensional Features and Heterogeneous Elasticity
We consider a seller who can dynamically adjust the price of a product at the individual customer level, by utilizing information about customers' characteristics encoded as a d-dimensional feature vector. We assume a personalized demand model, parameters of which depend on s out of the d features. The seller initially does not know the relationship between the customer features and the product demand, but learns this through sales observations over a selling horizon of T periods. We prove that the seller's expected regret, i.e., the revenue loss against a clairvoyant who knows the underlying demand relationship, is at least of order s√T under any admissible policy. We then design a near-optimal pricing policy for a "semi-clairvoyant" seller (who knows which s of the d features are in the demand model) that achieves an expected regret of order s√T log T. We extend this policy to a more realistic setting where the seller does not know the true demand predictors, and show that this policy has an expected regret of order s√T (log d+log T), which is also near-optimal. Finally, we test our theory on simulated data and on a data set from an online auto loan company in the United States. On both data sets, our experimentation-based pricing policy is superior to intuitive and/or widely-practiced customized pricing methods such as myopic pricing and segment-then-optimize policies. Furthermore, our policy improves upon the loan company's historical pricing decisions by 47% in expected revenue over a six-month period.

Traditional dynamic pricing methods#
Before machine learning became the default language for pricing optimization, businesses still changed prices dynamically. They used analysts, pricing managers, revenue managers, sales teams, business rules, spreadsheets, statistical reports, A/B testing, and operational experience.
From a machine learning lens, traditional dynamic pricing usually includes the following steps.
1. Monitor sales and pricing performance#
The first step is to understand the baseline. This means tracking sales volume, conversion, revenue, margin, inventory, time-to-sale, discounting, channel mix, and customer behaviour.
This gives the business a statistical picture of its current revenue process. Basic measures such as average demand, variance, seasonality, skewness, conversion rate, and moving averages become the foundation for any pricing model.
For many businesses, even this step is not trivial. If the data is messy, delayed, fragmented across systems, or disconnected from marketing and inventory data, advanced pricing models will not help much.
2. Monitor the market#
A business also needs to understand the market around it. Competitor pricing, substitute products, macroeconomic conditions, seasonality, local events, sentiment, and search behaviour can all influence demand.
In some markets, competitor data is directly observable. In others, it must be inferred through scraping, third-party data, public listings, market research, or proxy signals.
When competitor sales data is unavailable, simulation methods and scenario modeling can help estimate possible market responses.
3. Identify pricing factors#
Once sales and market patterns are visible, the next step is identifying which factors actually influence demand and revenue.
These factors may include:
- Price
- Discount depth
- Inventory level
- Time before event or expiration
- Customer segment
- Marketing campaign
- Day of week
- Seasonality
- Competitor price
- Product popularity
- Location
- Weather
- Channel
- Past purchase behaviour
- Brand strength
- Search demand
- Social sentiment
In machine learning terms, this becomes feature engineering. In business terms, it is the discipline of understanding what actually moves the market.
4. Define pricing strategy and policy#
Companies rarely want a model to optimize price without constraints. They usually have pricing principles and business rules.
For example:
- Do not reduce margin below a certain level.
- Do not increase prices more than a defined percentage in a short period.
- Do not undercut premium brand positioning.
- Do not change prices too frequently.
- Do not treat protected or sensitive customer groups unfairly.
- Do not allow automated pricing during crisis events.
- Keep sales team override rights for strategic accounts.
- Respect channel agreements and legal restrictions.
A dynamic pricing strategy is not just a mathematical objective. It is a business policy translated into a decision system.
5. Apply, monitor, and revise#
Pricing is iterative. A business tests a pricing strategy, measures outcomes, updates its assumptions, and adjusts.
The loop looks like this:
Analyze demand
Define pricing policy
Apply pricing changes
Measure outcomes
Update model or policy
Repeat
From a machine learning perspective, this resembles a learning loop. The system forms expectations, takes action, observes the market response, and updates its understanding.
The challenge is that markets are not stationary. Customer behaviour changes. Competitors respond. Economic conditions shift. Brand perception evolves. A model trained on last year's patterns may become unreliable when the underlying market changes.
Covid-19 was an extreme example. Many historical pricing models suddenly became less useful because the demand environment changed drastically. In smaller ways, the same thing happens all the time.
Selected research:
- Den Boer is a strong starting point for the broader research landscape around pricing and demand learning:

Science Direct
Dynamic pricing and learning: Historical origins, current research, and new directions
The topic of dynamic pricing and learning has received a considerable amount of attention in recent years, from different scientific communities. We survey these literature streams: we provide a brief introduction to the historical origins of quantitative research on pricing and demand estimation, point to different subfields in the area of dynamic pricing, and provide an in-depth overview of the available literature on dynamic pricing and learning. Our focus is on the operations research and management science literature, but we also discuss relevant contributions from marketing, economics, econometrics, and computer science. We discuss relations with methodologically related research areas, and identify directions for future research.
- Besbes and Zeevi formalize the problem of pricing when the firm does not know the demand function and must learn it while selling:

informs PubsOnline
Dynamic Pricing Without Knowing the Demand Function: Risk Bounds and Near-Optimal Algorithms
We consider a single-product revenue management problem where, given an initial inventory, the objective is to dynamically adjust prices over a finite sales horizon to maximize expected revenues. Realized demand is observed over time, but the underlying functional relationship between price and mean demand rate that governs these observations (otherwise known as the demand function or demand curve) is not known. We consider two instances of this problem: (i) a setting where the demand function is assumed to belong to a known parametric family with unknown parameter values; and (ii) a setting where the demand function is assumed to belong to a broad class of functions that need not admit any parametric representation. In each case we develop policies that learn the demand function “on the fly,” and optimize prices based on that. The performance of these algorithms is measured in terms of the regret: the revenue loss relative to the maximal revenues that can be extracted when the demand function is known prior to the start of the selling season. We derive lower bounds on the regret that hold for any admissible pricing policy, and then show that our proposed algorithms achieve a regret that is “close” to this lower bound. The magnitude of the regret can be interpreted as the economic value of prior knowledge on the demand function, manifested as the revenue loss due to model uncertainty.
- Phumchusri and Swann provide a useful sports and entertainment example using stochastic dynamic programs and Bayesian updates for event-ticket pricing:

Journal of Computer Science
DYNAMIC PRICING WITH UPDATED DEMAND FOR THE SPORTS AND ENTERTAINMENT TICKET INDUSTRY
Revenue Management (RM) helped increase profitability for many travel industries. Selling perishable products with a fixed event date, the Sports and Entertainment (S&E) ticket industry can potentially benefit from RM ideas but has received less attention in the literature. In this study we develop dynamic pricing models for stochastic S&E demand in a discrete finite time setting, where demand depends not only on ticket prices but also on remaining times until the show dates. We assume the show popularity is uncertain to the seller, but this information can be learned via Bayesian updates as early sales are revealed. We present stochastic dynamic programs for Sports and Entertainment tickets pricing decisions. We test the models using real data obtained from a major performance venue in the U.S. to understand properties of the model solutions and performance under different scenarios. Our results show that demand learning is most beneficial when the initial estimates are incorrect. In addition, we found it is less necessary for the seller to vary price every period if demand variation is low and/or a large amount of demand arrives close to the show dates. Overall, we found that the benefits from having flexibility of price changes and demand learning can complement each other to achieve as much as 8.15% revenue increase on average, as compared to static pricing.

How machine learning improves dynamic pricing#
Machine learning can improve dynamic pricing in several ways. The important point is that different methods solve different problems. A demand forecast is not an optimizer. A customer segmentation model is not a pricing policy. A reinforcement learning agent is not automatically safer or better than a well-designed rule-based system.
A mature pricing system usually combines multiple methods.
Demand forecasting#
Demand forecasting estimates future demand based on historical sales, seasonality, marketing activity, customer behaviour, macro conditions, competitor prices, and other signals.
Useful methods include:
- Linear and regularized regression
- Gradient boosted trees
- Random forests
- Classical time-series models
- Bayesian forecasting
- Neural networks
- Transformer-based forecasting models
- Hybrid statistical and ML models
A pricing team needs to know not only how much demand exists today, but how demand is likely to change over time. This is especially important for perishable inventory such as airline seats, hotel rooms, event tickets, advertising slots, or appointment capacity.
In 2026, the practical direction is not simply "replace ARIMA with deep learning." The better approach is to choose a forecasting model based on data volume, forecast horizon, interpretability needs, business cadence, and the availability of future-known covariates such as holidays, campaigns, event dates, and inventory constraints.
Classical time-series models are still useful when the pattern is stable and data is limited. Tree-based ML models are useful when structured features matter. Transformer-based forecasting models can be useful when the data has many time-varying inputs and the business needs multi-horizon forecasts.
Selected research and implementation references:
- Ferreira, Lee, and Simchi-Levi combine machine learning demand forecasting with price optimization in an online retail setting and report field-experiment results from Rue La La:

Manufacturing & Service Operations Management
Analytics for an Online Retailer: Demand Forecasting and Price Optimization
We present our work with an online retailer, Rue La La, as an example of how a retailer can use its wealth of data to optimize pricing decisions on a daily basis. Rue La La is in the online fashion sample sales industry, where they offer extremely limited-time discounts on designer apparel and accessories. One of the retailer’s main challenges is pricing and predicting demand for products that it has never sold before, which account for the majority of sales and revenue. To tackle this challenge, we use machine learning techniques to estimate historical lost sales and predict future demand of new products. The nonparametric structure of our demand prediction model, along with the dependence of a product’s demand on the price of competing products, pose new challenges on translating the demand forecasts into a pricing policy. We develop an algorithm to efficiently solve the subsequent multiproduct price optimization that incorporates reference price effects, and we create and implement this algorithm into a pricing decision support tool for Rue La La’s daily use. We conduct a field experiment and find that sales does not decrease because of implementing tool recommended price increases for medium and high price point products. Finally, we estimate an increase in revenue of the test group by approximately 9.7% with an associated 90% confidence interval of [2.3%, 17.8%].
- Taylor and Letham present Prophet, a practical analyst-in-the-loop approach for scalable forecasting:

The American Statistician
Forecasting at Scale
Forecasting is a common data science task that helps organizations with capacity planning, goal setting, and anomaly detection. Despite its importance, there are serious challenges associated with producing reliable and high-quality forecasts—especially when there are a variety of time series and analysts with expertise in time series modeling are relatively rare. To address these challenges, we describe a practical approach to forecasting “at scale” that combines configurable models with analyst-in-the-loop performance analysis. We propose a modular regression model with interpretable parameters that can be intuitively adjusted by analysts with domain knowledge about the time series. We describe performance analyses to compare and evaluate forecasting procedures, and automatically flag forecasts for manual review and adjustment. Tools that help analysts to use their expertise most effectively enable reliable, practical forecasting of business time series.
- Lim, Arik, Loeff, and Pfister introduce Temporal Fusion Transformers, which combine multi-horizon forecasting with interpretability mechanisms:
International Journal of Forecasting
Temporal Fusion Transformers for interpretable multi-horizon time series forecasting
Multi-horizon forecasting often contains a complex mix of inputs – including static (i.e. time-invariant) covariates, known future inputs, and other exogenous time series that are only observed in the past – without any prior information on how they interact with the target. Several deep learning methods have been proposed, but they are typically ‘black-box’ models that do not shed light on how they use the full range of inputs present in practical scenarios. In this paper, we introduce the Temporal Fusion Transformer (TFT) – a novel attention-based architecture that combines high-performance multi-horizon forecasting with interpretable insights into temporal dynamics. To learn temporal relationships at different scales, TFT uses recurrent layers for local processing and interpretable self-attention layers for long-term dependencies. TFT utilizes specialized components to select relevant features and a series of gating layers to suppress unnecessary components, enabling high performance in a wide range of scenarios. On a variety of real-world datasets, we demonstrate significant performance improvements over existing benchmarks, and highlight three practical interpretability use cases of TFT.
Price elasticity estimation#
Price elasticity measures how demand changes when price changes.
If a small price increase causes a large demand drop, demand is elastic. If demand remains stable despite a price increase, demand is inelastic.
This is one of the most important concepts in pricing. Without elasticity, a model may optimize short-term revenue in misleading ways.
For example, increasing price may raise revenue per unit but reduce conversion enough to lower total revenue. Reducing price may increase volume but reduce margin. The optimal decision depends on both demand response and business objective.
Elasticity is not always stable. It may vary by customer segment, time, product, channel, geography, competitor environment, reference price, inventory level, and brand strength.
A practical pricing team should think about elasticity at multiple levels:
- Product-level elasticity
- Segment-level elasticity
- Channel-level elasticity
- Time-based elasticity
- Cross-product elasticity
- Competitor-relative elasticity
- Long-term reference-price effects
One of the main mistakes in pricing analytics is estimating elasticity from observational data without accounting for the fact that prices were not randomly assigned. If high-demand products are also the ones where managers increased prices, a naive model may underestimate price sensitivity. This is why experiments, causal inference, and careful policy logging matter.
Selected research and implementation references:
- Broder and Rusmevichientong study dynamic pricing under a general parametric choice model where demand parameters are initially unknown and must be learned through sales observations:
Operations Research
Dynamic Pricing Under a General Parametric Choice Model
We consider a stylized dynamic pricing model in which a monopolist prices a product to a sequence of T customers who independently make purchasing decisions based on the price offered according to a general parametric choice model. The parameters of the model are unknown to the seller, whose objective is to determine a pricing policy that minimizes the regret, which is the expected difference between the seller's revenue and the revenue of a clairvoyant seller who knows the values of the parameters in advance and always offers the revenue-maximizing price. We show that the regret of the optimal pricing policy in this model is [Formula: see text], by establishing an [Formula: see text] lower bound on the worst-case regret under an arbitrary policy, and presenting a pricing policy based on maximum-likelihood estimation whose regret is [Formula: see text] across all problem instances. Furthermore, we show that when the demand curves satisfy a “well-separated” condition, the T-period regret of the optimal policy is Θ(log T). Numerical experiments show that our policies perform well.
- Ban and Keskin study personalized dynamic pricing with high-dimensional features and heterogeneous elasticity:
papers.ssrn.com
Personalized Dynamic Pricing with Machine Learning: High Dimensional Features and Heterogeneous Elasticity
We consider a seller who can dynamically adjust the price of a product at the individual customer level, by utilizing information about customers' characteristics encoded as a d-dimensional feature vector. We assume a personalized demand model, parameters of which depend on s out of the d features. The seller initially does not know the relationship between the customer features and the product demand, but learns this through sales observations over a selling horizon of T periods. We prove that the seller's expected regret, i.e., the revenue loss against a clairvoyant who knows the underlying demand relationship, is at least of order s√T under any admissible policy. We then design a near-optimal pricing policy for a "semi-clairvoyant" seller (who knows which s of the d features are in the demand model) that achieves an expected regret of order s√T log T. We extend this policy to a more realistic setting where the seller does not know the true demand predictors, and show that this policy has an expected regret of order s√T (log d+log T), which is also near-optimal. Finally, we test our theory on simulated data and on a data set from an online auto loan company in the United States. On both data sets, our experimentation-based pricing policy is superior to intuitive and/or widely-practiced customized pricing methods such as myopic pricing and segment-then-optimize policies. Furthermore, our policy improves upon the loan company's historical pricing decisions by 47% in expected revenue over a six-month period.
- Xu and Wang study contextual elasticity and heteroscedastic valuation in online contextual dynamic pricing:

PMLR
Pricing with Contextual Elasticity and Heteroscedastic Valuation
We study an online contextual dynamic pricing problem, where customers decide whether to purchase a product based on its features and price. We introduce a novel approach to modeling a customer’s e…
- Agrawal and Tang study long-term reference effects, where customers' price expectations are affected by historical prices:
arXiv.org
Dynamic Pricing and Learning with Long-term Reference Effects
We consider a dynamic pricing problem where customer response to the current price is impacted by the customer price expectation, aka reference price. We study a simple and novel reference price mechanism where reference price is the average of the past prices offered by the seller. As opposed to the more commonly studied exponential smoothing mechanism, in our reference price mechanism the prices offered by seller have a longer term effect on the future customer expectations. We show that under this mechanism, a markdown policy is near-optimal irrespective of the parameters of the model. This matches the common intuition that a seller may be better off by starting with a higher price and then decreasing it, as the customers feel like they are getting bargains on items that are ordinarily more expensive. For linear demand models, we also provide a detailed characterization of the near-optimal markdown policy along with an efficient way of computing it. We then consider a more challenging dynamic pricing and learning problem, where the demand model parameters are apriori unknown, and the seller needs to learn them online from the customers’ responses to the offered prices while simultaneously optimizing revenue. The objective is to minimize regret, i.e., the $T$-round revenue loss compared to a clairvoyant optimal policy. This task essentially amounts to learning a non-stationary optimal policy in a time-variant Markov Decision Process (MDP). For linear demand models, we provide an efficient learning algorithm with an optimal $\tilde{O}(\sqrt{T})$ regret upper bound.
Customer segmentation and personalized offers#
Machine learning can segment customers by behaviour, preferences, likelihood to convert, price sensitivity, loyalty, churn risk, lifetime value, and product interest.
Segmentation is often safer and more practical than fully personalized pricing. Instead of assigning a unique price to each customer, a business can design different offers, bundles, messages, or promotions for different groups.
Examples include:
- High-intent customers who need less discounting
- Price-sensitive customers who respond to promotions
- Loyal customers who value access or convenience
- New customers who need introductory offers
- At-risk customers who may need retention incentives
- Premium customers who prefer service quality over discounting
Segmentation is also useful because business teams can usually understand and act on it.
The important distinction is between personalized pricing and personalized offer design. Personalized pricing changes the price itself. Personalized offer design may change the bundle, message, loyalty benefit, payment plan, upgrade path, or limited-time incentive.
In many industries, personalized offer design creates much less customer backlash than invisible individualized price changes.
Selected research and implementation references:
- Ban and Keskin provide a formal treatment of personalized dynamic pricing with high-dimensional customer features:
papers.ssrn.com
Personalized Dynamic Pricing with Machine Learning: High Dimensional Features and Heterogeneous Elasticity
We consider a seller who can dynamically adjust the price of a product at the individual customer level, by utilizing information about customers' characteristics encoded as a d-dimensional feature vector. We assume a personalized demand model, parameters of which depend on s out of the d features. The seller initially does not know the relationship between the customer features and the product demand, but learns this through sales observations over a selling horizon of T periods. We prove that the seller's expected regret, i.e., the revenue loss against a clairvoyant who knows the underlying demand relationship, is at least of order s√T under any admissible policy. We then design a near-optimal pricing policy for a "semi-clairvoyant" seller (who knows which s of the d features are in the demand model) that achieves an expected regret of order s√T log T. We extend this policy to a more realistic setting where the seller does not know the true demand predictors, and show that this policy has an expected regret of order s√T (log d+log T), which is also near-optimal. Finally, we test our theory on simulated data and on a data set from an online auto loan company in the United States. On both data sets, our experimentation-based pricing policy is superior to intuitive and/or widely-practiced customized pricing methods such as myopic pricing and segment-then-optimize policies. Furthermore, our policy improves upon the loan company's historical pricing decisions by 47% in expected revenue over a six-month period.
- Javanmard and Nazerzadeh study high-dimensional dynamic pricing with product and customer features under sparsity assumptions:
arXiv.org
Dynamic Pricing in High-dimensions
We study the pricing problem faced by a firm that sells a large number of products, described via a wide range of features, to customers that arrive over time. Customers independently make purchasing decisions according to a general choice model that includes products features and customers’ characteristics, encoded as $d$-dimensional numerical vectors, as well as the price offered. The parameters of the choice model are a priori unknown to the firm, but can be learned as the (binary-valued) sales data accrues over time. The firm’s objective is to minimize the regret, i.e., the expected revenue loss against a clairvoyant policy that knows the parameters of the choice model in advance, and always offers the revenue-maximizing price. This setting is motivated in part by the prevalence of online marketplaces that allow for real-time pricing. We assume a structured choice model, parameters of which depend on $s_0$ out of the $d$ product features. We propose a dynamic policy, called Regularized Maximum Likelihood Pricing (RMLP) that leverages the (sparsity) structure of the high-dimensional model and obtains a logarithmic regret in $T$. More specifically, the regret of our algorithm is of $O(s_0 \log d \cdot \log T)$. Furthermore, we show that no policy can obtain regret better than $O(s_0 (\log d + \log T))$.
- Chen, Simchi-Levi, and Wang introduce fairness constraints into contextual dynamic pricing with demand learning, which is highly relevant when segmentation becomes personalized pricing:

informs PubsOnline
Utility Fairness in Contextual Dynamic Pricing with Demand Learning
This paper introduces a novel contextual bandit algorithm for personalized pricing under utility fairness constraints in scenarios with uncertain demand, achieving an optimal regret upper bound. Our approach, which incorporates dynamic pricing and demand learning, addresses the critical challenge of fairness in pricing strategies. We first delve into the static full-information setting to formulate an optimal pricing policy as a constrained optimization problem. Here, we propose an approximation algorithm for efficiently and approximately computing the ideal policy. We also use mathematical analysis and computational studies to characterize the structures of optimal contextual pricing policies subject to fairness constraints, deriving simplified policies that lay the foundations of more in-depth research and extensions. Further, we extend our study to dynamic pricing problems with demand learning, establishing a nonstandard regret lower bound that highlights the complexity added by fairness constraints. Our research offers a comprehensive analysis of the cost of fairness and its impact on the balance between utility and revenue maximization. This work represents a step toward integrating ethical considerations into algorithmic efficiency in data-driven dynamic pricing.
Competitor analysis and market response#
In competitive markets, dynamic pricing is not only about internal demand. It is also about predicting how the market will respond.
Machine learning can help monitor competitor pricing and detect patterns in competitor behaviour.
For example:
- Which competitors change prices most often?
- Which products are used as price anchors?
- Which competitors follow each other?
- How quickly does demand respond after a competitor price change?
- When do promotions appear?
- Which market conditions trigger discounting?
- Which competitor movements are noise, and which require a response?
The practical challenge is that competitor prices are visible, but competitor demand is usually not visible. That means the model often observes what competitors did, but not what they sold, what inventory they had, or what margin constraints they faced.
This is why competitor-aware dynamic pricing should not be a simple rule like "match the lowest price." That can destroy margins and train the market into a discount race. A better approach is to estimate competitor relevance by segment, product, channel, and context.
Selected research and implementation references:
- Van de Geer, Schlosser, Bischl, and other participants analyzed dynamic pricing and learning under competition through the INFORMS Dynamic Pricing Challenge:
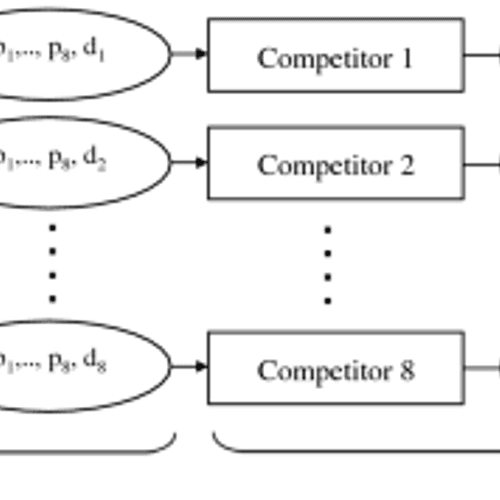
Journal of Revenue and Pricing Management
Dynamic pricing and learning with competition: insights from the dynamic pricing challenge at the 2017 INFORMS RM & pricing conference
This paper presents the results of the Dynamic Pricing Challenge, held on the occasion of the 17th INFORMS Revenue Management and Pricing Section Conference on June 29–30, 2017 in Amsterdam, The Netherlands. For this challenge, participants submitted algorithms for pricing and demand learning of which the numerical performance was analyzed in simulated market environments. This allows consideration of market dynamics that are not analytically tractable or can not be empirically analyzed due to practical complications. Our findings implicate that the relative performance of algorithms varies substantially across different market dynamics, which confirms the intrinsic complexity of pricing and learning in the presence of competition.
- Kastius and Schlosser study reinforcement learning under competitive pricing settings and discuss dynamic pricing, e-commerce, and price-collusion concerns:
Journal of Revenue and Pricing Management
Dynamic pricing under competition using reinforcement learning
AbstractDynamic pricing is considered a possibility to gain an advantage over competitors in modern online markets. The past advancements in Reinforcement Learning (RL) provided more capable algorithms that can be used to solve pricing problems. In this paper, we study the performance of Deep Q-Networks (DQN) and Soft Actor Critic (SAC) in different market models. We consider tractable duopoly settings, where optimal solutions derived by dynamic programming techniques can be used for verification, as well as oligopoly settings, which are usually intractable due to the curse of dimensionality. We find that both algorithms provide reasonable results, while SAC performs better than DQN. Moreover, we show that under certain conditions, RL algorithms can be forced into collusion by their competitors without direct communication.
- Calvano, Calzolari, Denicolò, and Pastorello show that Q-learning pricing algorithms can learn supracompetitive prices in repeated oligopoly simulations, even without explicit communication:

American Economic Review
Artificial Intelligence, Algorithmic Pricing, and Collusion
Increasingly, algorithms are supplanting human decision-makers in pricing goods and services. To analyze the possible consequences, we study experimentally the behavior of algorithms powered by Artificial Intelligence (Q-learning) in a workhorse oligopoly model of repeated price competition. We find that the algorithms consistently learn to charge supracompetitive prices, without communicating with one another. The high prices are sustained by collusive strategies with a finite phase of punishment followed by a gradual return to cooperation. This finding is robust to asymmetries in cost or demand, changes in the number of players, and various forms of uncertainty. (JEL D21, D43, D83, L12, L13)
Bayesian models and online demand learning#
Bayesian methods are useful when uncertainty matters and the system needs to update beliefs as new data arrives.
This is common when:
- Historical data is limited.
- Demand is uncertain.
- Inventory is perishable.
- New products are introduced.
- The business wants probabilistic forecasts.
- Pricing decisions must balance exploration and exploitation.
Bayesian approaches can help a business avoid overconfidence. Instead of saying "demand will be 1,000 units," a Bayesian model can say "demand is likely to fall within this range, given current evidence."
That uncertainty range can be very valuable for pricing decisions.
For example, consider an event with limited inventory. Early sales may reveal whether demand is stronger or weaker than expected. A Bayesian pricing system can update its belief about demand as sales arrive, then adjust the remaining pricing strategy.
This is often more realistic than pretending the firm knows the demand function from the beginning.
Selected research and implementation references:
- Besbes and Zeevi are foundational for dynamic pricing when the demand function is unknown and must be learned during the selling horizon:
informs PubsOnline
Dynamic Pricing Without Knowing the Demand Function: Risk Bounds and Near-Optimal Algorithms
We consider a single-product revenue management problem where, given an initial inventory, the objective is to dynamically adjust prices over a finite sales horizon to maximize expected revenues. Realized demand is observed over time, but the underlying functional relationship between price and mean demand rate that governs these observations (otherwise known as the demand function or demand curve) is not known. We consider two instances of this problem: (i) a setting where the demand function is assumed to belong to a known parametric family with unknown parameter values; and (ii) a setting where the demand function is assumed to belong to a broad class of functions that need not admit any parametric representation. In each case we develop policies that learn the demand function “on the fly,” and optimize prices based on that. The performance of these algorithms is measured in terms of the regret: the revenue loss relative to the maximal revenues that can be extracted when the demand function is known prior to the start of the selling season. We derive lower bounds on the regret that hold for any admissible pricing policy, and then show that our proposed algorithms achieve a regret that is “close” to this lower bound. The magnitude of the regret can be interpreted as the economic value of prior knowledge on the demand function, manifested as the revenue loss due to model uncertainty.
- Phumchusri and Swann apply Bayesian demand learning to sports and entertainment ticket pricing:
Journal of Computer Science
DYNAMIC PRICING WITH UPDATED DEMAND FOR THE SPORTS AND ENTERTAINMENT TICKET INDUSTRY
Revenue Management (RM) helped increase profitability for many travel industries. Selling perishable products with a fixed event date, the Sports and Entertainment (S&E) ticket industry can potentially benefit from RM ideas but has received less attention in the literature. In this study we develop dynamic pricing models for stochastic S&E demand in a discrete finite time setting, where demand depends not only on ticket prices but also on remaining times until the show dates. We assume the show popularity is uncertain to the seller, but this information can be learned via Bayesian updates as early sales are revealed. We present stochastic dynamic programs for Sports and Entertainment tickets pricing decisions. We test the models using real data obtained from a major performance venue in the U.S. to understand properties of the model solutions and performance under different scenarios. Our results show that demand learning is most beneficial when the initial estimates are incorrect. In addition, we found it is less necessary for the seller to vary price every period if demand variation is low and/or a large amount of demand arrives close to the show dates. Overall, we found that the benefits from having flexibility of price changes and demand learning can complement each other to achieve as much as 8.15% revenue increase on average, as compared to static pricing.
- Agrawal and Tang study dynamic pricing and learning when historical prices shape long-term reference-price expectations:
arXiv.org
Dynamic Pricing and Learning with Long-term Reference Effects
We consider a dynamic pricing problem where customer response to the current price is impacted by the customer price expectation, aka reference price. We study a simple and novel reference price mechanism where reference price is the average of the past prices offered by the seller. As opposed to the more commonly studied exponential smoothing mechanism, in our reference price mechanism the prices offered by seller have a longer term effect on the future customer expectations. We show that under this mechanism, a markdown policy is near-optimal irrespective of the parameters of the model. This matches the common intuition that a seller may be better off by starting with a higher price and then decreasing it, as the customers feel like they are getting bargains on items that are ordinarily more expensive. For linear demand models, we also provide a detailed characterization of the near-optimal markdown policy along with an efficient way of computing it. We then consider a more challenging dynamic pricing and learning problem, where the demand model parameters are apriori unknown, and the seller needs to learn them online from the customers’ responses to the offered prices while simultaneously optimizing revenue. The objective is to minimize regret, i.e., the $T$-round revenue loss compared to a clairvoyant optimal policy. This task essentially amounts to learning a non-stationary optimal policy in a time-variant Markov Decision Process (MDP). For linear demand models, we provide an efficient learning algorithm with an optimal $\tilde{O}(\sqrt{T})$ regret upper bound.
- Correa, Mari, and Xia study Bayesian updates from online reviews, a useful example of combining market feedback with pricing:
arXiv.org
Dynamic pricing with Bayesian updates from online reviews
When launching new products, firms face uncertainty about market reception. Online reviews provide valuable information not only to consumers but also to firms, allowing firms to adjust the product characteristics, including its selling price. In this paper, we consider a pricing model with online reviews in which the quality of the product is uncertain, and both the seller and the buyers Bayesianly update their beliefs to make purchasing & pricing decisions. We model the seller’s pricing problem as a basic bandits’ problem and show a close connection with the celebrated Catalan numbers, allowing us to efficiently compute the overall future discounted reward of the seller. With this tool, we analyze and compare the optimal static and dynamic pricing strategies in terms of the probability of effectively learning the quality of the product.
Multi-armed bandits and contextual bandits#
Bandit algorithms are useful when the system needs to learn while making decisions.
A simple A/B test may assign traffic evenly between options. A bandit approach can gradually shift more traffic toward better-performing options while still exploring alternatives.
This can be useful for:
- Promotion testing
- Offer selection
- Discount depth
- Product recommendations
- Email incentives
- Marketplace incentives
- Price ladder testing
A contextual bandit extends this idea by using context, such as product, customer, inventory, time, and channel features. This is closer to real dynamic pricing because not every customer, product, or market condition should receive the same treatment.
The risk is that bandits may optimize short-term performance while missing long-term effects such as customer trust, brand damage, delayed churn, or training customers to wait for discounts.
Bandits also need careful exploration design. Randomly testing prices can be expensive, unfair, or legally sensitive. In many real settings, the exploration policy must be approval-gated, constrained, or first tested in simulation.
Selected research and implementation references:
- Broder and Rusmevichientong frame dynamic pricing as a learning problem under unknown choice-model parameters:
Operations Research
Dynamic Pricing Under a General Parametric Choice Model
We consider a stylized dynamic pricing model in which a monopolist prices a product to a sequence of T customers who independently make purchasing decisions based on the price offered according to a general parametric choice model. The parameters of the model are unknown to the seller, whose objective is to determine a pricing policy that minimizes the regret, which is the expected difference between the seller's revenue and the revenue of a clairvoyant seller who knows the values of the parameters in advance and always offers the revenue-maximizing price. We show that the regret of the optimal pricing policy in this model is [Formula: see text], by establishing an [Formula: see text] lower bound on the worst-case regret under an arbitrary policy, and presenting a pricing policy based on maximum-likelihood estimation whose regret is [Formula: see text] across all problem instances. Furthermore, we show that when the demand curves satisfy a “well-separated” condition, the T-period regret of the optimal policy is Θ(log T). Numerical experiments show that our policies perform well.
- Chen, Simchi-Levi, and Wang connect contextual bandits, dynamic pricing, and fairness constraints:
informs PubsOnline
Utility Fairness in Contextual Dynamic Pricing with Demand Learning
This paper introduces a novel contextual bandit algorithm for personalized pricing under utility fairness constraints in scenarios with uncertain demand, achieving an optimal regret upper bound. Our approach, which incorporates dynamic pricing and demand learning, addresses the critical challenge of fairness in pricing strategies. We first delve into the static full-information setting to formulate an optimal pricing policy as a constrained optimization problem. Here, we propose an approximation algorithm for efficiently and approximately computing the ideal policy. We also use mathematical analysis and computational studies to characterize the structures of optimal contextual pricing policies subject to fairness constraints, deriving simplified policies that lay the foundations of more in-depth research and extensions. Further, we extend our study to dynamic pricing problems with demand learning, establishing a nonstandard regret lower bound that highlights the complexity added by fairness constraints. Our research offers a comprehensive analysis of the cost of fairness and its impact on the balance between utility and revenue maximization. This work represents a step toward integrating ethical considerations into algorithmic efficiency in data-driven dynamic pricing.
- Zhao, Jiang, and Yu study contextual dynamic pricing under local differential privacy constraints:
arXiv.org
Contextual Dynamic Pricing: Algorithms, Optimality, and Local Differential Privacy Constraints
We study contextual dynamic pricing problems where a firm sells products to $T$ sequentially-arriving consumers, behaving according to an unknown demand model. The firm aims to minimize its regret over a clairvoyant that knows the model in advance. The demand follows a generalized linear model (GLM), allowing for stochastic feature vectors in $\mathbb R^d$ encoding product and consumer information. We first show the optimal regret is of order $\sqrt{dT}$, up to logarithmic factors, improving existing upper bounds by a $\sqrt{d}$ factor. This optimal rate is materialized by two algorithms: a confidence bound-type algorithm and an explore-then-commit (ETC) algorithm. A key insight is an intrinsic connection between dynamic pricing and contextual multi-armed bandit problems with many arms with a careful discretization. We further study contextual dynamic pricing under local differential privacy (LDP) constraints. We propose a stochastic gradient descent-based ETC algorithm achieving regret upper bounds of order $d\sqrt{T}/ε$, up to logarithmic factors, where $ε>0$ is the privacy parameter. The upper bounds with and without LDP constraints are matched by newly constructed minimax lower bounds, characterizing costs of privacy. Moreover, we extend our study to dynamic pricing under mixed privacy constraints, improving the privacy-utility tradeoff by leveraging public data. This is the first time such setting is studied in the dynamic pricing literature and our theoretical results seamlessly bridge dynamic pricing with and without LDP. Extensive numerical experiments and real data applications are conducted to illustrate the efficiency and practical value of our algorithms.
- Kohavi, Longbotham, Sommerfield, and Henne provide a practical foundation for online controlled experiments, which are still essential when pricing changes need causal measurement:

Data Mining and Knowledge Discovery
Controlled experiments on the web: survey and practical guide
The web provides an unprecedented opportunity to evaluate ideas quickly using controlled experiments, also called randomized experiments, A/B tests (and their generalizations), split tests, Control/Treatment tests, MultiVariable Tests (MVT) and parallel flights. Controlled experiments embody the best scientific design for establishing a causal relationship between changes and their influence on user-observable behavior. We provide a practical guide to conducting online experiments, where end-users can help guide the development of features. Our experience indicates that significant learning and return-on-investment (ROI) are seen when development teams listen to their customers, not to the Highest Paid Person’s Opinion (HiPPO). We provide several examples of controlled experiments with surprising results. We review the important ingredients of running controlled experiments, and discuss their limitations (both technical and organizational). We focus on several areas that are critical to experimentation, including statistical power, sample size, and techniques for variance reduction. We describe common architectures for experimentation systems and analyze their advantages and disadvantages. We evaluate randomization and hashing techniques, which we show are not as simple in practice as is often assumed. Controlled experiments typically generate large amounts of data, which can be analyzed using data mining techniques to gain deeper understanding of the factors influencing the outcome of interest, leading to new hypotheses and creating a virtuous cycle of improvements. Organizations that embrace controlled experiments with clear evaluation criteria can evolve their systems with automated optimizations and real-time analyses. Based on our extensive practical experience with multiple systems and organizations, we share key lessons that will help practitioners in running trustworthy controlled experiments.
Reinforcement learning#
Reinforcement learning is attractive because pricing is naturally sequential. A price decision today can influence demand tomorrow, competitor response, customer expectations, and future inventory.
Reinforcement learning can model pricing as a Markov Decision Process, where the system observes a state, takes an action, receives a reward, and learns over time.
A simplified version looks like this:
- State:
demand, inventory, time, competitor prices, customer segment, historical sales - Action:
choose price, discount, bundle, or offer - Reward:
revenue, profit, conversion, utilization, or long-term value - Policy:
learn which action works best in each state
Reinforcement learning can be useful in high-volume digital environments, but it is also risky.
The risks include:
- Poor explainability
- Unsafe exploration
- Customer trust damage
- Regulatory exposure
- Collusion-like behaviour in competitive markets
- Overfitting to simulated environments
- Optimizing the wrong reward
- Difficulty proving causality
- Operational complexity
For most businesses, reinforcement learning should be introduced carefully. A safer path is often simulation first, then offline evaluation, then constrained experiments, then limited production use with guardrails.
Selected research and implementation references:
- Liu, Zhang, Wang, Deng, and Wu present a deep reinforcement learning framework for e-commerce dynamic pricing using Alibaba/Tmall data and field experiments:
arXiv.org
Dynamic Pricing on E-commerce Platform with Deep Reinforcement Learning: A Field Experiment
In this paper we present an end-to-end framework for addressing the problem of dynamic pricing (DP) on E-commerce platform using methods based on deep reinforcement learning (DRL). By using four groups of different business data to represent the states of each time period, we model the dynamic pricing problem as a Markov Decision Process (MDP). Compared with the state-of-the-art DRL-based dynamic pricing algorithms, our approaches make the following three contributions. First, we extend the discrete set problem to the continuous price set. Second, instead of using revenue as the reward function directly, we define a new function named difference of revenue conversion rates (DRCR). Third, the cold-start problem of MDP is tackled by pre-training and evaluation using some carefully chosen historical sales data. Our approaches are evaluated by both offline evaluation method using real dataset of Alibaba Inc., and online field experiments starting from July 2018 with thousands of items, lasting for months on Tmall.com. To our knowledge, there is no other DP field experiment using DRL before. Field experiment results suggest that DRCR is a more appropriate reward function than revenue, which is widely used by current literature. Also, continuous price sets have better performance than discrete sets and our approaches significantly outperformed the manual pricing by operation experts.
- Kastius and Schlosser compare reinforcement learning algorithms in competitive dynamic pricing settings:
Journal of Revenue and Pricing Management
Dynamic pricing under competition using reinforcement learning
AbstractDynamic pricing is considered a possibility to gain an advantage over competitors in modern online markets. The past advancements in Reinforcement Learning (RL) provided more capable algorithms that can be used to solve pricing problems. In this paper, we study the performance of Deep Q-Networks (DQN) and Soft Actor Critic (SAC) in different market models. We consider tractable duopoly settings, where optimal solutions derived by dynamic programming techniques can be used for verification, as well as oligopoly settings, which are usually intractable due to the curse of dimensionality. We find that both algorithms provide reasonable results, while SAC performs better than DQN. Moreover, we show that under certain conditions, RL algorithms can be forced into collusion by their competitors without direct communication.
- Calvano, Calzolari, Denicolò, and Pastorello show why algorithmic pricing governance matters, because learning agents can converge to supracompetitive pricing in repeated competition:
American Economic Review
Artificial Intelligence, Algorithmic Pricing, and Collusion
Increasingly, algorithms are supplanting human decision-makers in pricing goods and services. To analyze the possible consequences, we study experimentally the behavior of algorithms powered by Artificial Intelligence (Q-learning) in a workhorse oligopoly model of repeated price competition. We find that the algorithms consistently learn to charge supracompetitive prices, without communicating with one another. The high prices are sustained by collusive strategies with a finite phase of punishment followed by a gradual return to cooperation. This finding is robust to asymmetries in cost or demand, changes in the number of players, and various forms of uncertainty. (JEL D21, D43, D83, L12, L13)
- Deng, Schiffer, and Bichler provide a 2024 deep reinforcement learning view of algorithmic collusion risks in dynamic pricing:
arXiv.org
Algorithmic Collusion in Dynamic Pricing with Deep Reinforcement Learning
Nowadays, a significant share of the Business-to-Consumer sector is based on online platforms like Amazon and Alibaba and uses Artificial Intelligence for pricing strategies. This has sparked debate on whether pricing algorithms may tacitly collude to set supra-competitive prices without being explicitly designed to do so. Our study addresses these concerns by examining the risk of collusion when Reinforcement Learning algorithms are used to decide on pricing strategies in competitive markets. Prior research in this field focused on Tabular Q-learning (TQL) and led to opposing views on whether learning-based algorithms can lead to supra-competitive prices. Our work contributes to this ongoing discussion by providing a more nuanced numerical study that goes beyond TQL by additionally capturing off- and on-policy Deep Reinforcement Learning (DRL) algorithms. We study multiple Bertrand oligopoly variants and show that algorithmic collusion depends on the algorithm used. In our experiments, TQL exhibits higher collusion and price dispersion phenomena compared to DRL algorithms. We show that the severity of collusion depends not only on the algorithm used but also on the characteristics of the market environment. We further find that Proximal Policy Optimization appears to be less sensitive to collusive outcomes compared to other state-of-the-art DRL algorithms.
LLM-based methods in 2026#
Large language models are now part of the pricing conversation, but they should not be misunderstood.
An LLM should generally not be asked to "guess the right price" from a prompt. That is not a pricing system. A real pricing system needs structured data, demand estimates, elasticity estimates, business constraints, experimentation, and governance.
Where LLMs are useful is around the pricing model, not as a replacement for the pricing model.
1. LLMs as text-to-structure layers#
Pricing teams deal with a lot of unstructured information:
- Competitor product pages
- Promotion terms
- Customer reviews
- Sales-call notes
- Support tickets
- Contracts
- RFPs
- News and local events
- Product descriptions
- Marketplace listings
- Policy and compliance documents
LLMs can extract structured features from this text. For example, an LLM can turn competitor promotion pages into structured fields such as discount depth, dates, eligible products, exclusions, and shipping terms. Those fields can then feed a proper forecasting or optimization model.
2. LLMs as pricing copilots#
LLMs can help humans understand pricing recommendations.
For example, an LLM can summarize:
- Why the model recommends a price change
- Which demand signals changed
- Which constraints are active
- Which competitors moved
- Which segments are affected
- What risks the pricing team should review
- Whether the recommendation violates an internal pricing policy
This is especially useful when pricing is approval-gated. The LLM can produce a decision brief, but the actual numeric recommendation should come from a statistical model, optimizer, or rules engine.
3. LLMs as agentic orchestrators#
In an agentic architecture, the LLM can coordinate tools:
LLM agent
reads pricing question
calls demand forecasting model
calls elasticity model
calls inventory service
calls competitor-pricing service
calls optimization engine
checks governance rules
drafts recommendation for a human pricing owner
This is the pattern I trust most. The LLM handles language, workflow, explanation, and tool orchestration. The numeric pricing decision comes from models designed for pricing.
4. LLMs as market simulation agents#
LLM agents can also be used to simulate buyers, sellers, or competitors in market games. This is useful for research and scenario exploration, but it is still early. LLM behaviour can change across models, providers, prompts, and versions. A simulation result should not be confused with proof of real market behaviour.
5. LLMs as a new pricing domain#
There is also a second meaning of LLM pricing: pricing the LLM service itself. As AI providers sell models through token-based, tiered, fine-tuned, and routed services, LLM services have become a new pricing problem. That is not the same as using LLMs to set retail prices, but it is highly relevant to modern AI economics.
Selected research and implementation references:
- Giebel, Rösner, and Schröder study LLM agents in a repeated Bertrand pricing game and find coordinated pricing outcomes, with communication increasing prices and the likelihood of identical prices. This is a 2026 SSRN working paper, so I would treat it as emerging evidence rather than settled literature:
papers.ssrn.com
Artificial Intelligence, Communication, and Strategic Pricing: Evidence from Large Language Models
We analyze the behavior of large language model (LLM) agents as strategic actors in a price-setting environment. In an experimental market based on a repeated Bertrand pricing game, we find that LLM agents generate coordinated pricing outcomes. Allowing agents to communicate increases prices and profits while reducing variation in both outcomes. Moreover, communication increases the likelihood that agents coordinate on identical prices. Analyzing communication patterns shows that more frequent, longer, and more explicit exchanges reinforce these outcomes. A detailed analysis of agents' decision rationales suggests that communication affects pricing less through explicit game-theoretic reasoning than through reinforcement by cooperative language and pattern completion. Further tests involving different LLM temperature settings, varying the number of interacting agents, and various LLM architectures show that the results hold across these conditions. This consistency can be attributed mainly to language adjustments across different conditions. Overall, these findings highlight how language-based artificial intelligence systems can generate coordinated market outcomes even without specialized training in pricing or strategic interaction.
- Guo, Bai, and Jin present a 2026 AAAI paper on pricing online LLM services with a data-calibrated Stackelberg routing game:

ojs.aaai.org
Pricing Online LLM Services with Data-Calibrated Stackelberg Routing Game
The proliferation of Large Language Models (LLMs) has established LLM routing as a standard service delivery mechanism, where users select models based on cost, Quality of Service (QoS), among other things. However, optimal pricing in LLM routing platforms requires precise modeling for dynamic service markets, and solving this problem in real time at scale is computationally intractable. In this paper, we propose PriLLM, a novel practical and scalable solution for real-time dynamic pricing in competitive LLM routing. PriLLM models the service market as a Stackelberg game, where providers set prices and users select services based on multiple criteria. To capture real-world market dynamics, we incorporate both objective factors (eg cost, QoS) and subjective user preferences into the model. For scalability, we employ a deep aggregation network to learn provider abstraction that preserve user-side equilibrium behavior across pricing strategies. Moreover, PriLLM offers interpretability by explaining its pricing decisions. Empirical evaluation on real-world data shows that PriLLM achieves over 95% of the optimal profit while only requiring less than 5% of the optimal solution's computation time.
- Bergemann, Bonatti, and Smolin model the economics of LLM services, including token allocation, fine-tuning, and optimal pricing:
arXiv.org
Menu Pricing of Large Language Models
We develop a framework for the optimal pricing and product design of LLMs in which a provider sells menus of token budgets to users who differ in their valuations across a continuum of tasks. Under a homogeneous production technology, we show that users’ high-dimensional type profiles are summarized by a scalar index, reducing the seller’s problem to one-dimensional screening. The optimal mechanism takes the form of committed-spend contracts: buyers pay for a budget that they allocate across token classes priced at marginal cost. We extend the analysis to environments with multiple differentiated models and to competition between a proprietary leader and an open-source fringe, showing that competitive pressure reshapes both the intensive and extensive margins of compute provision. Each element of our theory (token-budget menus, maximum- and minimum-spend plans, multi-model versioning, and linear API pricing) has a direct counterpart in the observed pricing practices of providers such as Anthropic, OpenAI, and GitHub.
- Calvano et al. remain essential background because LLM agents used in pricing systems can inherit the broader algorithmic-pricing risk of supracompetitive outcomes in repeated market interactions:
American Economic Review
Artificial Intelligence, Algorithmic Pricing, and Collusion
Increasingly, algorithms are supplanting human decision-makers in pricing goods and services. To analyze the possible consequences, we study experimentally the behavior of algorithms powered by Artificial Intelligence (Q-learning) in a workhorse oligopoly model of repeated price competition. We find that the algorithms consistently learn to charge supracompetitive prices, without communicating with one another. The high prices are sustained by collusive strategies with a finite phase of punishment followed by a gradual return to cooperation. This finding is robust to asymmetries in cost or demand, changes in the number of players, and various forms of uncertainty. (JEL D21, D43, D83, L12, L13)
The practical conclusion for 2026 is simple: use LLMs to structure information, explain recommendations, coordinate tools, and support governance. Do not let them directly invent prices without a quantitative pricing model and a controlled decision process.
A practical architecture for ML-driven dynamic pricing#
A production pricing system needs more than a model. It needs a full decision architecture.
A practical architecture has six layers.
1. Data layer#
The system needs reliable inputs.
Typical data sources include:
- Historical sales
- Product catalog
- Inventory or capacity
- Customer profiles
- Web and app behaviour
- CRM data
- Marketing campaigns
- Competitor prices
- Seasonality
- Promotions
- Returns and cancellations
- Support complaints
- Macroeconomic signals
- Weather or local events
- Channel data
- Margin and cost data
- Policy and compliance rules
Poor data quality is one of the fastest ways to damage a pricing system.
2. Feature and context layer#
This layer turns raw data into useful pricing context.
Examples include:
- Days until event or expiration
- Remaining inventory ratio
- Recent demand velocity
- Competitor price gap
- Segment-level conversion rate
- Promotion exposure
- Customer lifetime value band
- Prior discount sensitivity
- Channel margin
- Local-event indicator
- Weather indicator
- Search-demand index
- Customer-support complaint trend
This is where LLMs can help if source data is unstructured, but the output should be validated and stored as structured features.
3. Prediction layer#
This layer estimates what is likely to happen.
It may include:
- Demand forecasting
- Conversion prediction
- Price elasticity estimation
- Churn prediction
- Customer lifetime value
- Inventory depletion forecasting
- Competitor response prediction
- Promotion response modeling
This layer does not need to set prices directly. It creates intelligence that can support pricing decisions.
4. Decision layer#
This is where recommendations or price changes are generated.
The decision layer may include:
- Optimization models
- Business rules
- Margin constraints
- Inventory constraints
- Brand rules
- Fairness rules
- Legal restrictions
- Human approval thresholds
- Experimentation policies
- Channel-specific rules
This is often where many real-world systems fail. The model may be technically strong, but the decision layer is not aligned with how the business actually operates.
5. Execution layer#
The decision must reach the market.
Execution channels may include:
- E-commerce pricing
- App pricing
- Sales team recommendations
- CRM campaigns
- Email offers
- Paid media audiences
- Call-center scripts
- Point-of-sale systems
- Marketplace listings
- Partner channels
A model that produces recommendations but never changes behaviour is not a pricing system. It is a report.
6. Monitoring and governance layer#
Every pricing system needs monitoring.
Key monitoring areas include:
- Revenue
- Margin
- Conversion
- Inventory utilization
- Customer complaints
- Refunds and cancellations
- Price volatility
- Segment-level outcomes
- Model drift
- Data drift
- Fairness concerns
- Competitive response
- Long-term retention
- Override frequency
- Experiment results
Governance is not a bureaucratic add-on. It is what keeps pricing intelligence commercially safe.
Selected research and implementation references:
- Ferreira, Lee, and Simchi-Levi are useful for seeing how prediction and optimization can be combined in a production decision-support tool:
Manufacturing & Service Operations Management
Analytics for an Online Retailer: Demand Forecasting and Price Optimization
We present our work with an online retailer, Rue La La, as an example of how a retailer can use its wealth of data to optimize pricing decisions on a daily basis. Rue La La is in the online fashion sample sales industry, where they offer extremely limited-time discounts on designer apparel and accessories. One of the retailer’s main challenges is pricing and predicting demand for products that it has never sold before, which account for the majority of sales and revenue. To tackle this challenge, we use machine learning techniques to estimate historical lost sales and predict future demand of new products. The nonparametric structure of our demand prediction model, along with the dependence of a product’s demand on the price of competing products, pose new challenges on translating the demand forecasts into a pricing policy. We develop an algorithm to efficiently solve the subsequent multiproduct price optimization that incorporates reference price effects, and we create and implement this algorithm into a pricing decision support tool for Rue La La’s daily use. We conduct a field experiment and find that sales does not decrease because of implementing tool recommended price increases for medium and high price point products. Finally, we estimate an increase in revenue of the test group by approximately 9.7% with an associated 90% confidence interval of [2.3%, 17.8%].
- Chen, Simchi-Levi, and Wang are useful for integrating fairness into contextual dynamic pricing:
informs PubsOnline
Utility Fairness in Contextual Dynamic Pricing with Demand Learning
This paper introduces a novel contextual bandit algorithm for personalized pricing under utility fairness constraints in scenarios with uncertain demand, achieving an optimal regret upper bound. Our approach, which incorporates dynamic pricing and demand learning, addresses the critical challenge of fairness in pricing strategies. We first delve into the static full-information setting to formulate an optimal pricing policy as a constrained optimization problem. Here, we propose an approximation algorithm for efficiently and approximately computing the ideal policy. We also use mathematical analysis and computational studies to characterize the structures of optimal contextual pricing policies subject to fairness constraints, deriving simplified policies that lay the foundations of more in-depth research and extensions. Further, we extend our study to dynamic pricing problems with demand learning, establishing a nonstandard regret lower bound that highlights the complexity added by fairness constraints. Our research offers a comprehensive analysis of the cost of fairness and its impact on the balance between utility and revenue maximization. This work represents a step toward integrating ethical considerations into algorithmic efficiency in data-driven dynamic pricing.
- Kohavi, Tang, and Xu provide practical guidance for trustworthy online experimentation, which is essential when pricing systems move from recommendation to action:

Cambridge Core
Trustworthy Online Controlled Experiments
Cambridge Core - Knowledge Management, Databases and Data Mining - Trustworthy Online Controlled Experiments
Lessons from revenue optimization in live events#
My own experience with pricing-adjacent work comes primarily from revenue optimization, customer intelligence, and AI-driven commercial decisioning in live events.
In live-event environments, pricing is rarely just a model that changes prices. The useful intelligence layer combines demand forecasting, inventory constraints, customer segmentation, timing, campaign performance, sales prioritization, and business rules.
When I led AI and data strategy at Churchill Downs, the broader commercial problem was not only "what should this price be?" It was:
- Which demand signals should matter?
- Which customers or leads are most likely to convert?
- Which inventory is constrained?
- Which campaigns are working?
- Which sales opportunities should be prioritized?
- How should the business act while there is still time to influence revenue?
- Which decisions should be automated and which should stay human-owned?
That experience is highly relevant to dynamic pricing because dynamic pricing depends on the same intelligence layer.
A pricing model cannot operate well if it does not understand demand, timing, inventory, customer intent, channel behaviour, and business constraints. In high-stakes environments such as major events, the model also needs to respect operational reality. Sales, marketing, analytics, finance, and leadership all need to understand and trust the decision process.
This is why I prefer to frame the mature version of dynamic pricing as revenue decisioning. Price is one lever. The broader system decides how to use data to improve commercial outcomes.
Selected research and implementation references:
- Phumchusri and Swann show how demand learning can improve sports and entertainment ticket pricing when demand is uncertain:
thescipub.com
https://thescipub.com/abstract/10.3844/jcssp.2014.2240.2252
- Dutta studies capacity allocation of game tickets using dynamic pricing and discusses sports-ticket conditions such as fixed capacity, perishable inventory, market segmentation, and fluctuating demand:

MDPI Data
Capacity Allocation of Game Tickets Using Dynamic Pricing
This study examines a pricing approach that is applicable in the field of online ticket sales for game tickets. The mathematical principle of dynamic programing is combined with empirical data analysis to determine demand functions for university football game tickets. Based on the calculated demand functions, the application of DP strategies is found to generate more revenues than a fixed price strategy. The other important result is the capacity distribution of tickets according to the football game intensity. Prior studies have shown that it is sometimes more profitable or football clubs to allocate a share of tickets to a retailer and earn a commission based on the sales, rather than selling the entire capacity of tickets by itself. This paper finds that in a high intensity game, where the demand is generally high, it is optimal for the club to sell all tickets by itself. Whereas, for less popular games, where there is considerable fluctuation in demand, the capacity allocation problem for maximized revenues from ticket sales, becomes a harder optimization challenge for the club. According to DP optimization, when the demand for tickets is relatively low, it is optimal for the club to retain 20–40% of the tickets and the rest of the capacity should be sold to online retailers. In the real world, this pricing technique has been used by football clubs and thus the secondary market online retailers like Ticketmaster and Vivid Seats have become popular in the last decade.
Evaluation: what should a dynamic pricing system optimize?#
Many teams start with revenue. That is understandable, but revenue alone is not enough.
A dynamic pricing system may need to optimize or balance:
- Gross revenue
- Net revenue
- Margin
- Conversion rate
- Inventory utilization
- Customer lifetime value
- Retention
- Market share
- Sell-through rate
- Average order value
- Profit per available unit
- Customer acquisition cost
- Promotion efficiency
- Fairness and trust
- Brand position
- Sales team productivity
A pricing model can hit its revenue target while damaging margin, loyalty, or brand trust. It can also improve short-term conversion while training customers to wait for discounts.
The evaluation framework should match the business strategy. A premium brand, a marketplace, a SaaS product, and a live-event venue should not all optimize the same objective.
The reward function matters. In reinforcement learning, for example, optimizing immediate revenue may produce a different policy than optimizing margin, long-term value, or customer retention. In bandits, optimizing short-term conversion may over-discount. In forecasting, optimizing prediction accuracy may not improve pricing outcomes if the forecast is not causal.
This is why the best pricing systems are not only predictive. They are decision-aware.
The part most teams underestimate: governance#
Dynamic pricing can create real business risk.
Customers may accept price changes when they understand them. For example, people generally understand that flights are more expensive during holidays or that hotels cost more during major events.
But customers react differently when they believe prices are unfair, exploitative, personalized in a creepy way, or changing too often without justification.
Governance should address questions such as:
- Which variables are allowed to influence price?
- Which variables are prohibited?
- How often can prices change?
- What is the maximum allowed price movement?
- When does a human need to approve a change?
- How do we explain the pricing logic internally?
- How do we detect bias or unfair outcomes?
- How do we monitor complaints?
- How do we prevent margin leakage?
- How do we stop the system during abnormal events?
- Who owns the model?
- Who owns the business outcome?
A pricing model without governance is not an advanced system. It is an unmanaged risk.
In 2026, this is not theoretical. Algorithmic pricing is receiving more attention from competition policy, consumer protection, and state-level disclosure laws. Even if a system is technically legal, the business still needs to ask whether customers, regulators, and internal leaders would consider it explainable and fair.
Selected research and implementation references:
- Calvano et al. are essential reading for algorithmic collusion risk:
American Economic Review
Artificial Intelligence, Algorithmic Pricing, and Collusion
Increasingly, algorithms are supplanting human decision-makers in pricing goods and services. To analyze the possible consequences, we study experimentally the behavior of algorithms powered by Artificial Intelligence (Q-learning) in a workhorse oligopoly model of repeated price competition. We find that the algorithms consistently learn to charge supracompetitive prices, without communicating with one another. The high prices are sustained by collusive strategies with a finite phase of punishment followed by a gradual return to cooperation. This finding is robust to asymmetries in cost or demand, changes in the number of players, and various forms of uncertainty.
- Chen, Simchi-Levi, and Wang provide a formal treatment of fairness constraints in contextual dynamic pricing:
informs PubsOnline
Utility Fairness in Contextual Dynamic Pricing with Demand Learning
This paper introduces a novel contextual bandit algorithm for personalized pricing under utility fairness constraints in scenarios with uncertain demand, achieving an optimal regret upper bound. Our approach, which incorporates dynamic pricing and demand learning, addresses the critical challenge of fairness in pricing strategies. We first delve into the static full-information setting to formulate an optimal pricing policy as a constrained optimization problem. Here, we propose an approximation algorithm for efficiently and approximately computing the ideal policy. We also use mathematical analysis and computational studies to characterize the structures of optimal contextual pricing policies subject to fairness constraints, deriving simplified policies that lay the foundations of more in-depth research and extensions. Further, we extend our study to dynamic pricing problems with demand learning, establishing a nonstandard regret lower bound that highlights the complexity added by fairness constraints. Our research offers a comprehensive analysis of the cost of fairness and its impact on the balance between utility and revenue maximization. This work represents a step toward integrating ethical considerations into algorithmic efficiency in data-driven dynamic pricing.
- New York's legislative activity around algorithmic pricing disclosure shows how pricing algorithms are becoming a consumer-protection issue, not only a modeling issue:

New York State Senate
Senate Bill S7033, Enacts the preventing algorithmic pricing discrimination act
Establishes the Preventing Algorithmic Pricing Discrimination Act. This bill prohibits the use of surveillance pricing practices that adjust the cost of goods and services based on consumer data in a discriminatory manner. It ensures that businesses cannot use consumer data to infer personal characteristics such as race, gender, or disability status to alter prices unfairly. Additionally, the bill mandates that businesses utilizing surveillance pricing must notify consumers when prices are determined algorithmically based on their personal data.
Where dynamic pricing should be used carefully#
Dynamic pricing is not appropriate everywhere.
It should be used carefully when:
- Customers are vulnerable.
- Prices relate to essential goods or services.
- The market is highly regulated.
- The model may infer sensitive attributes.
- Price differences are difficult to explain.
- The product has strong emotional or social importance.
- Demand spikes during emergencies.
- Competitor algorithms may interact in unpredictable ways.
- Customer trust is more valuable than short-term optimization.
The model may be mathematically correct and still be commercially wrong.
This is especially true for personalized pricing. A business should ask whether the customer would still trust the brand if they understood how the price was determined. If the answer is no, the strategy needs to be reconsidered.
A practical implementation roadmap#
For most organizations, the best path is not to start with reinforcement learning or LLM agents. The better path is to build pricing maturity in stages.
Stage 1: Pricing visibility#
Build clean reporting around:
- Sales
- Revenue
- Margin
- Inventory
- Discounts
- Conversion
- Channel mix
- Customer segment
- Time to purchase
- Competitor prices
Many organizations discover that they do not yet have a reliable pricing data foundation.
Stage 2: Forecasting and elasticity#
Build demand forecasts and elasticity estimates. Start with interpretable models and validate them against historical outcomes and controlled experiments.
The goal is not model sophistication. The goal is decision usefulness.
Stage 3: Decision support#
Use the models to generate recommendations for pricing teams, revenue managers, sales teams, or marketers.
At this stage, humans still approve the action.
Stage 4: Controlled experiments#
Run controlled experiments where appropriate. Use A/B tests, geo tests, holdouts, or carefully designed price ladders.
This helps the business learn causal effects rather than relying only on correlations.
Stage 5: Constrained automation#
Automate low-risk decisions under clear rules.
For example:
- Recommend discount ranges.
- Adjust prices within small limits.
- Trigger promotions for low-risk segments.
- Update prices only during approved windows.
- Require approval for large movements.
Stage 6: Advanced optimization#
Only after the basics are working should the business consider advanced methods such as reinforcement learning, contextual bandits, or agentic LLM orchestration.
At this stage, governance, monitoring, and rollback mechanisms are not optional.
A simple decision guide#
Use this as a practical guide.
Business problem | Useful method | Watch out for |
|---|---|---|
Forecast next week's demand | Time-series forecasting, gradient boosting, TFT | Forecast accuracy does not equal pricing lift |
Estimate demand response to price | Elasticity modeling, causal inference, experiments | Observational bias |
Choose among discount levels | A/B testing, contextual bandits | Short-term conversion bias |
Price perishable inventory | Bayesian learning, dynamic programming, revenue management | Overreacting to early noisy signals |
Price in competitive markets | Competitor modeling, game-theoretic simulation | Margin-destroying price wars |
Optimize sequential pricing | Reinforcement learning | Unsafe exploration and weak explainability |
Explain recommendations | LLM pricing copilot | Hallucinated reasoning |
Extract pricing signals from text | LLM information extraction | Data quality and validation |
Approve high-impact price changes | Human-in-the-loop workflow | Slow execution if the process is too heavy |
Govern personalized pricing | Fairness constraints, policy rules, audits | Customer trust and regulatory exposure |
Conclusion#
Dynamic pricing is no longer just a pricing tactic. In modern businesses, it is part of a broader revenue decisioning system.
The best systems combine:
- Clean data
- Demand forecasting
- Elasticity estimation
- Customer segmentation
- Competitor analysis
- Experimentation
- Business rules
- Optimization
- Governance
- Human accountability
Machine learning improves dynamic pricing when it helps the business make better commercial decisions. It fails when it becomes a black box that optimizes a narrow reward function without understanding the market, the customer, or the consequences.
In 2026, LLMs add a new layer to this architecture. They can extract context, coordinate tools, summarize evidence, explain recommendations, and help humans review pricing decisions. But they should not replace the statistical and economic machinery of pricing. A language model can help reason about the decision. It should not be the sole source of the price.
The strongest way to think about dynamic pricing is not:
How can we change prices automatically?
It is:
How can we use data, models, experiments, and governance to make better revenue decisions at the right time?
That is the real opportunity.
References and further reading#
- Arnoud V. den Boer, "Dynamic pricing and learning: Historical origins, current research, and new directions," Surveys in Operations Research and Management Science, 2015. https://doi.org/10.1016/j.sorms.2015.03.001
- Régis Y. Chenavaz and Stanko Dimitrov, "Artificial intelligence and dynamic pricing: a systematic literature review," Journal of Revenue and Pricing Management related literature, 2025. https://doi.org/10.1080/15140326.2025.2466140
- Omar Besbes and Assaf Zeevi, "Dynamic Pricing Without Knowing the Demand Function," Operations Research, 2009. https://doi.org/10.1287/opre.1080.0640
- Kris Johnson Ferreira, Bin Hong Alex Lee, and David Simchi-Levi, "Analytics for an Online Retailer: Demand Forecasting and Price Optimization," Manufacturing & Service Operations Management, 2016. https://doi.org/10.1287/msom.2015.0561
- Gah-Yi Ban and N. Bora Keskin, "Personalized Dynamic Pricing with Machine Learning: High-Dimensional Features and Heterogeneous Elasticity," Management Science, 2021. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2972985
- Josef Broder and Paat Rusmevichientong, "Dynamic Pricing Under a General Parametric Choice Model," Operations Research, 2012. https://doi.org/10.1287/opre.1120.1057
- Jianyu Xu and Yu-Xiang Wang, "Pricing with Contextual Elasticity and Heteroscedastic Valuation," ICML, 2024. https://proceedings.mlr.press/v235/xu24x.html
- Shipra Agrawal and Wei Tang, "Dynamic Pricing and Learning with Long-term Reference Effects," 2024. https://arxiv.org/abs/2402.12562
- Sean J. Taylor and Benjamin Letham, "Forecasting at Scale," The American Statistician, 2018. https://doi.org/10.1080/00031305.2017.1380080
- Bryan Lim, Sercan O. Arik, Nicolas Loeff, and Tomas Pfister, "Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting," International Journal of Forecasting, 2021. https://doi.org/10.1016/j.ijforecast.2021.03.012
- Xi Chen, David Simchi-Levi, and Yining Wang, "Utility Fairness in Contextual Dynamic Pricing with Demand Learning," Management Science, 2025. https://doi.org/10.1287/mnsc.2023.03956
- Ron Kohavi, Roger Longbotham, Dan Sommerfield, and Randal M. Henne, "Controlled experiments on the web: survey and practical guide," Data Mining and Knowledge Discovery, 2009. https://doi.org/10.1007/s10618-008-0114-1
- Ron Kohavi, Diane Tang, and Ya Xu, "Trustworthy Online Controlled Experiments," Cambridge University Press, 2020. https://doi.org/10.1017/9781108653985
- Jiaxi Liu, Yidong Zhang, Xiaoqing Wang, Yuming Deng, and Xingyu Wu, "Dynamic Pricing on E-commerce Platform with Deep Reinforcement Learning," 2019. https://arxiv.org/abs/1912.02572
- Alexander Kastius and Rainer Schlosser, "Dynamic pricing under competition using reinforcement learning," Journal of Revenue and Pricing Management, 2022. https://doi.org/10.1057/s41272-021-00285-3
- Emilio Calvano, Giacomo Calzolari, Vincenzo Denicolò, and Sergio Pastorello, "Artificial Intelligence, Algorithmic Pricing, and Collusion," American Economic Review, 2020. https://doi.org/10.1257/aer.20190623
- Shidi Deng, Maximilian Schiffer, and Martin Bichler, "Algorithmic Collusion in Dynamic Pricing with Deep Reinforcement Learning," 2024. https://arxiv.org/abs/2406.02437
- Naragain Phumchusri and Julie L. Swann, "Dynamic Pricing with Updated Demand for the Sports and Entertainment Ticket Industry," Journal of Computer Science, 2014. https://doi.org/10.3844/jcssp.2014.2240.2252
- Goutam Dutta, "Capacity Allocation of Game Tickets Using Dynamic Pricing," Data, 2019. https://www.mdpi.com/2306-5729/4/4/141
- Marek Giebel, Anja Rösner, and Benjamin Schröder, "Artificial Intelligence, Communication, and Strategic Pricing: Evidence from Large Language Models," SSRN, 2026. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6832662
- Zeyu Guo, Wenyuan Bai, and Jian Jin, "Pricing Online LLM Services with Data-Calibrated Stackelberg Routing Game," AAAI, 2026. https://doi.org/10.1609/aaai.v40i20.38748
- Dirk Bergemann, Alessandro Bonatti, and Alex Smolin, "The Economics of Large Language Models: Token Allocation, Fine-Tuning, and Optimal Pricing," 2025. https://arxiv.org/abs/2502.07736